How Jenkins Age Becomes Tech Debt
15 Jul 2025Jenkins is a very popular and highly customisable CI system. It is so customisable that it could even become a problem, especially if you use plugins.
I am maintaining a really old and weird CI system. The master worked on 2.289, which dates back to 2021. What is even worse is that agent machines were running the operating systems openSUSE 12 and Debian 7 from 2011 and 2013. Those were glorious times — the Higgs boson was discovered, athletes ran at the London Olympics, and Snowden leaked tons of classified data. Anyway, I didn’t think it was such an ancient system – master was only five years ago. How naive was I…
The Plan
The usual upgrade plan for Jenkins is:
- Upgrade plugins
- Restart
- Upgrade Jenkins WAR to the next version
- Restart
- Upgrade plugins again because Jenkins is newer now
- Enjoy
And it usually works – but not this time.
Plugins disaster
 Image by Jenkins Project CC BY-SA 3.0
Image by Jenkins Project CC BY-SA 3.0
Of course, I didn’t upgrade to the version past 2.479 on Java 17, because Debian 10 only supports OpenJDK 11 out of the box. So it was the easy part.
Then an innocent plugin upgrade led to unforeseen circumstances. It turns out the plugin centre doesn’t provide data for plugins older than one year. It is documented with an obscure wording: “Do not use versions no longer supported by the update centre”. I think it’s crucial information and providing factually incorrect information is just wrong. In practice, it means that you could be provided with an ill-defined set of versions without a proper baseline Jenkins version check.
That’s exactly what happened in my case. I discovered Jenkins in a state where almost all plugins complained about incompatibility with the Jenkins version. I started downgrading them one by one. It’s quite difficult since the Jenkins update centre doesn’t provide a way to downgrade a plugin version, not to mention downgrading to a specific version.
It means that for each plugin, you must navigate to the plugins website, perform version bisecting for a plugin version targeting Jenkins 2.479 at most, download the HPI from releases, upload it to the Jenkins Plugin Manager, and restart. Of course, the dependency graph for failed plugins must be constructed by yourself! The easiest way is to find the most used plugin, whose node has the highest out-degree in the graph, and try to upgrade it. Then move to dependencies. Hopefully, you won’t encounter plugin conflicts with each other (I did).
After a few hours, the plugin hell was finally frozen, and all plugins and Jenkins were in a consistent state with plugins.
In search of OpenJDK
Jenkins agents must run the same version of JDK as the master, or newer. This fact made life a little more complicated, since Debian 7 only supported Java 7, and openSUSE was stuck at 6. Previously, I put OpenJDK 8 in /opt/jdk8 and specified the path to the JDK binary for Jenkins agent in “Launch Method -> Advanced -> JavaPath” without exposing this Java to the system or applications via the environment. It worked well.
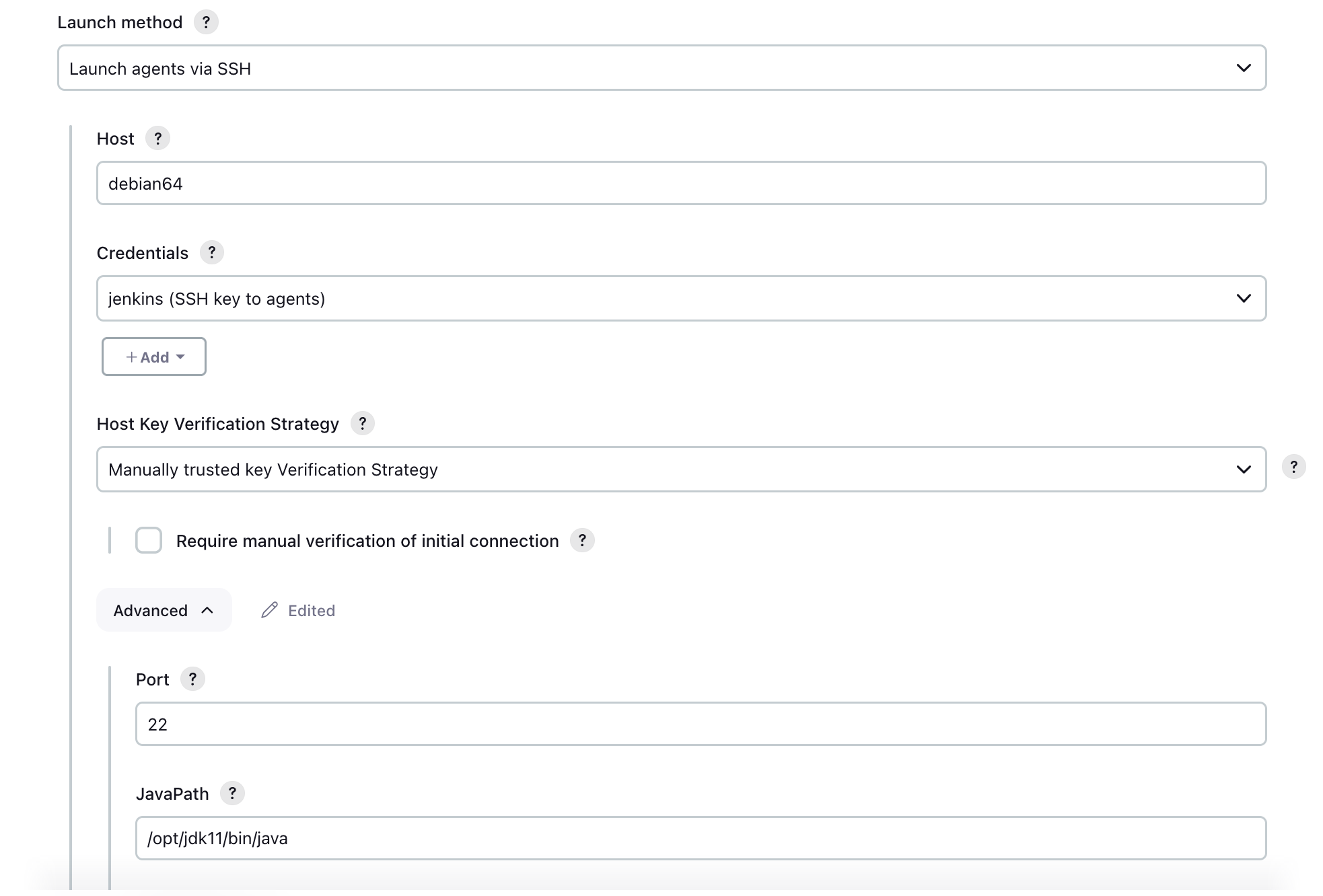
Unfortunately, JDK 11 builds are not widely available for these operating systems. Ten years ago, we were able to navigate to the Sun Microsystems Oracle website and download JDK builds for a variety of Unix systems. Sometimes, after an easy registration wall, but it was possible at least, although the options were limited.
Nowadays, Oracle doesn’t provide free JDK builds. The stewardship of Java went to OpenJDK, which is the official reference Java implementation. It produces source code, but not distributions. Surely, you can compile it on your own, but testing, tracking security issues, and ensuring correct platform support are up to you. So, plenty of JDK distributions had emerged (alphabetically):
- AdoptOpenJDK
- Azul Zulu
- Amazon Corretto
- Eclipse Temurin
- Liberica OpenJDK
- Microsoft OpenJDK
- Oracle Java
- Red Hat OpenJDK
To be precise, Oracle provides support only for the latest JDK version, so there is no such thing as Oracle LTS.
So the plan is to go and grab any distribution for OpenJDK 11, right? That’s true only if it supports an old enough libc. If somebody builds a distribution on a newer build machine, binaries will use the latest system glibc; hence, it cannot be run on an older machine. So you should either have a dedicated old build machine, which sets a baseline glibc version, or bump glibc requirements.
I found a few distributions which were built a long time ago and are still available at a vendor’s website. For example, for Liberica jdk11.0.27+9:
% nm /opt/jdk11/bin/java | grep '@GLIBC'
U getenv@@GLIBC_2.2.5
% /lib/x86_64-linux-gnu/libc.so.6
GNU C Library (Debian EGLIBC 2.13-38+deb7u11) stable release version 2.13, by Roland McGrath et al.
It works because the system glibc version is newer than any symbol referenced from the Java ELF binary. Of course, it is even easier just to launch it and see whether it immediately emits any errors.
Sometimes vendors are kind enough to list system requirements for versions in terms of operating system versions (like Debian 9, RedHat 7 and so on). Only a few of them specify the kernel and glibc version, and in this case one can consult distrowatch or check the glibc version on a real system. Finding a matching and working version was a trial-and-error process.
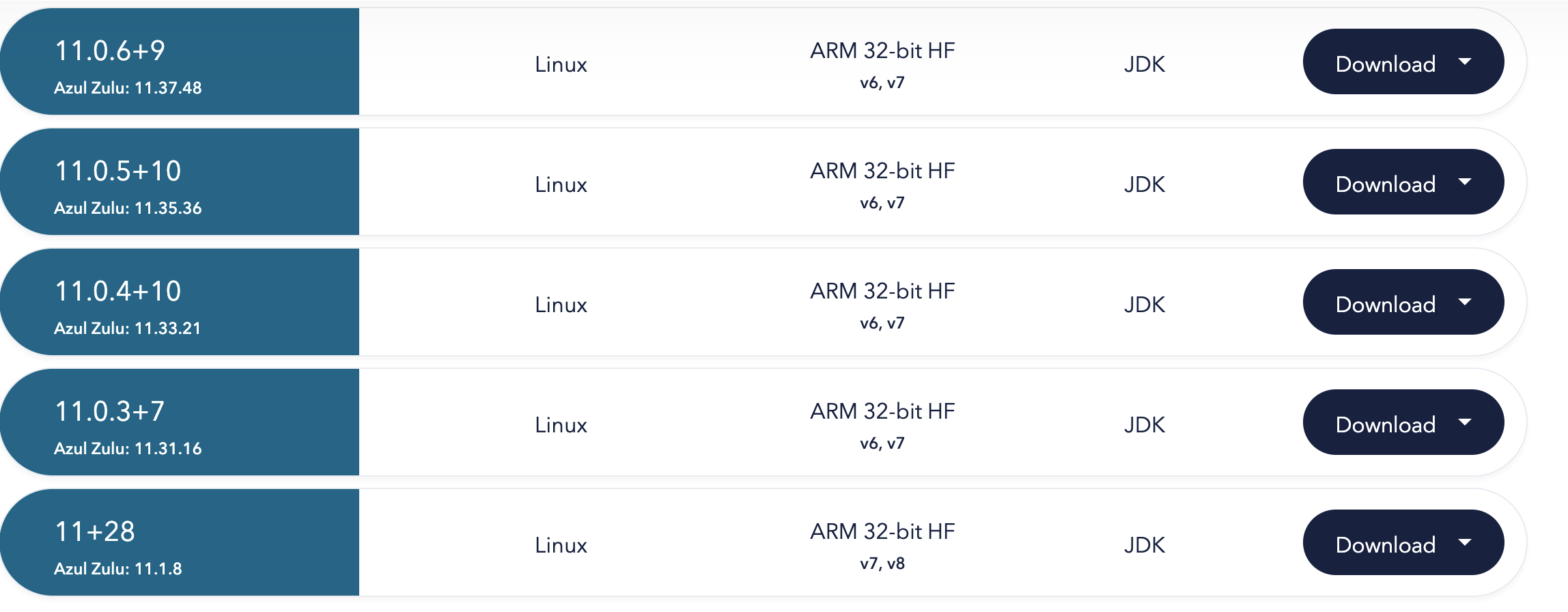
Things became even more complicated for non-Intel build farms. If you’re thinking about a modern AArch64 ARM – no way, it is a 32-bit ARM7 hard-float. So you have an even smaller chance of finding a binary distribution for this old obscure architecture. The only distribution providing 32-bit ARM7 HF is Azul Zulu. However, all of their recent binaries are for glibc 2.15. And there is only one old build 11.1.8 targeting older glibc 2.13, which is able to run on that machine:
The fun doesn’t stop with Linux. Turns out, an old but stable OS X 10.7 machine cannot run any builds from OpenJDK, Azul, or Corretto. It is not only a matter of using a new operating system API, but also of using a newer kernel. All these builds crashed with SIGSEGV upon launch. Suddenly, I discovered a custom OpenJDK build from the open-source enthusiast Jazzzny, who had kindly built JDK 11 for OS X. The binaries are available at GitHub releases page, and binary jdk-11-snowleopard-r1.pkg (sha256 7c51f13993a7f38575d82aa2a7691aace6170c59074847e779a3d9f903f044fb) built for Snow Leopard (10.7) worked perfectly for me. Minecraft gamers used these builds to deal with older Java versions, which proves again that gaming is the driving force of the computer industry.
Outcome
Ten hours into the upgrade, I’d successfully fixed core Jenkins, all the plugins, and agents, and I was able to run a few test builds.
What went well? The diversity of OpenJDK distributions and the openness of the community greatly enhance your chances of finding a proper distribution suited to your needs.
What could go better? The Jenkins plugin management system. The older your system is, the less likely you are able to upgrade. The cut-off of the plugin compatibility information after a year or two, lack of built-in downgrade functionality and clear machine-readable requirement annotation drags you into the manual dependency resolution nightmare. Making a copy of the Jenkins installation for upgrading and switching it later could be a good solution.
What had I learned? The age of your CI infrastructure is the tech debt. Contrary to popular opinion, please do upgrade your Jenkins at the LTS track and the plugins, at least yearly. It enables the possibility of a much smoother upgrade.